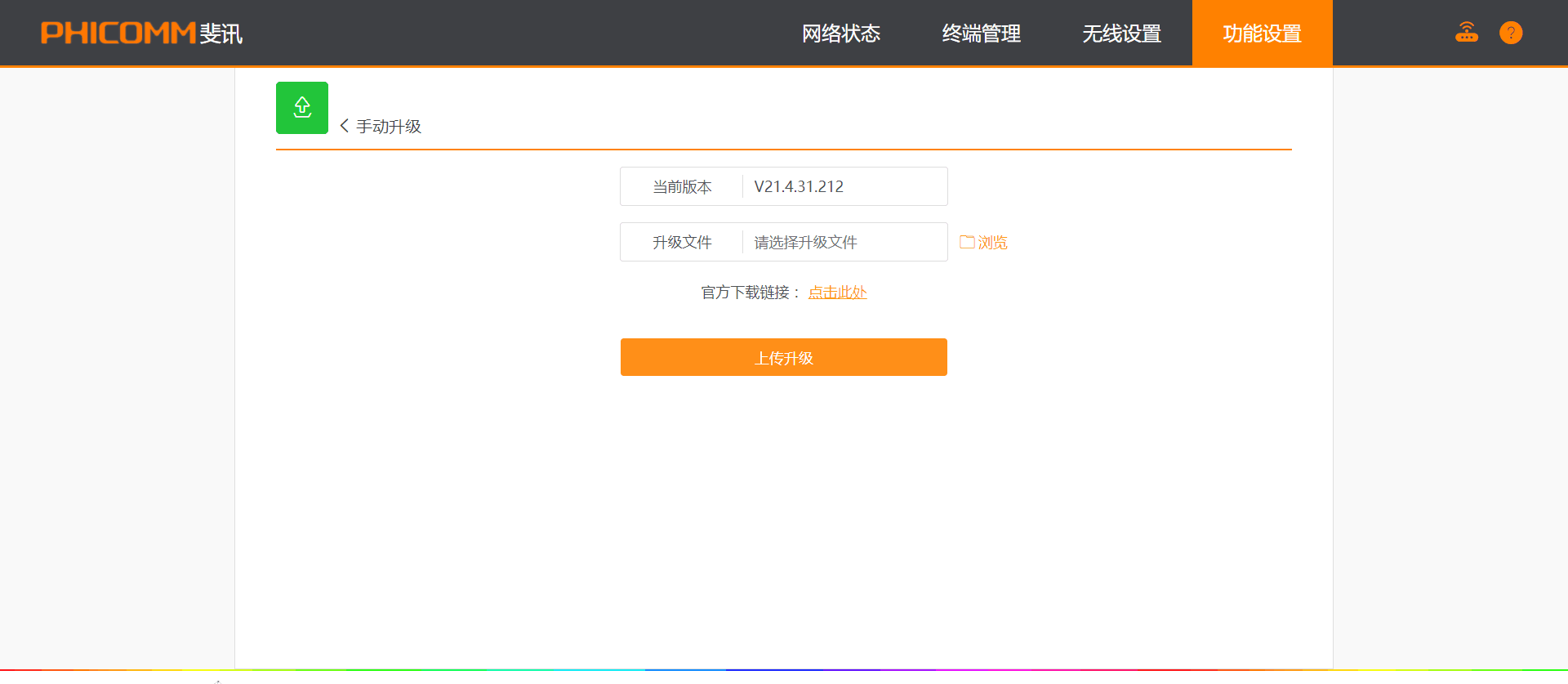
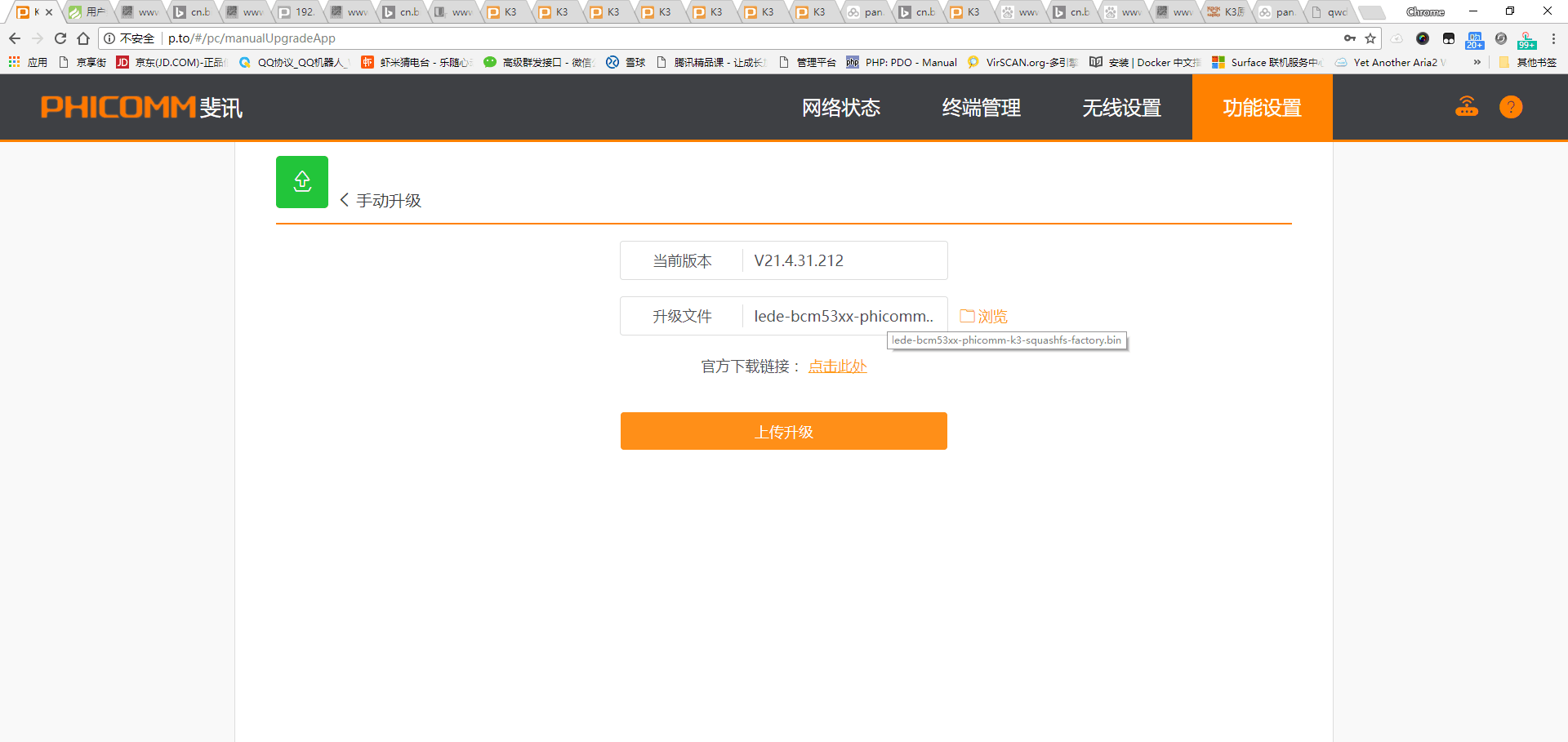
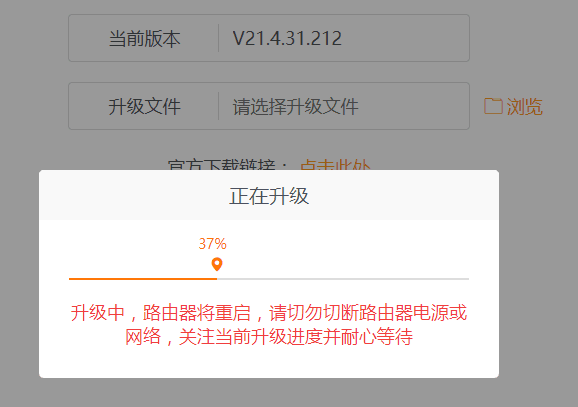
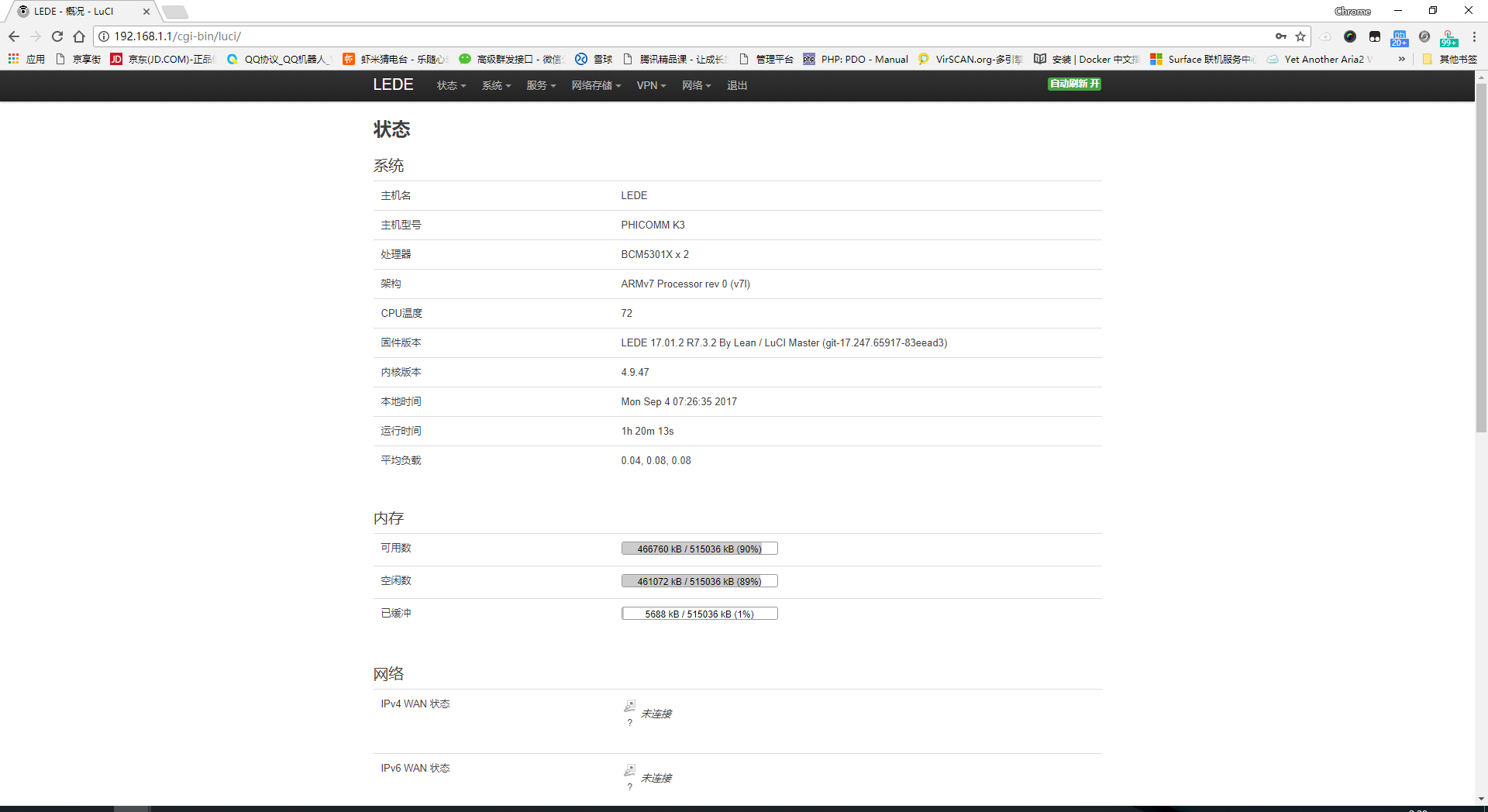
请使用chrome,firefox等现代浏览器访问。这两个东西都可以直接使用,除了看英文不爽以外,有什么必要下载回来使用?(吐槽:难道你们就不觉得webui-aria2的title总是被压成好几行,诡异的配色(对,说的就是那个蓝色背景,深蓝颜色的 Use custom IP and port settings 按钮)不难看吗?) 图形界面基本都基于RPC模式,所以一定确定开启了RPC,IP端口可访问,并且在管理器中填写了正确的地址。
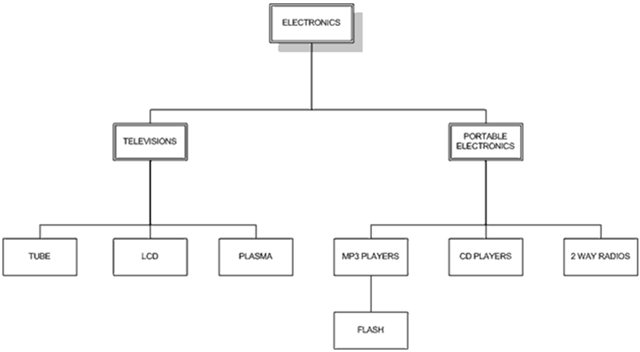
SELECT t1.name AS lev1, t2.name as lev2, t3.name as lev3, t4.name as lev4 FROM category AS t1 LEFT JOIN category AS t2 ON t2.parent = t1.category_id LEFT JOIN category AS t3 ON t3.parent = t2.category_id LEFT JOIN category AS t4 ON t4.parent = t3.category_id WHERE t1.name = 'ELECTRONICS';
SELECT t1.name FROM category AS t1 LEFT JOIN category as t2 ON t1.category_id = t2.parent WHERE t2.category_id IS NULL;
+--------------+ | name | +--------------+ | TUBE | | LCD | | PLASMA | | FLASH | | CD PLAYERS | | 2 WAY RADIOS | +--------------+
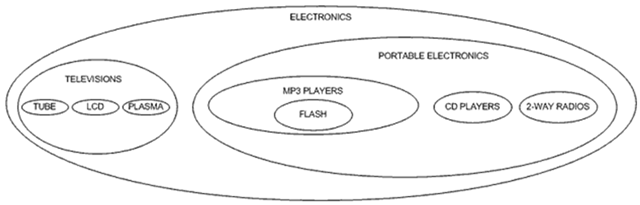
检索单一路径 通过自连接,我们也可以检索出单一路径:
1 2 3 4 5 6 7 8 9 10 11 12 13
SELECT t1.name AS lev1, t2.name as lev2, t3.name as lev3, t4.name as lev4 FROM category AS t1 LEFT JOIN category AS t2 ON t2.parent = t1.category_id LEFT JOIN category AS t3 ON t3.parent = t2.category_id LEFT JOIN category AS t4 ON t4.parent = t3.category_id WHERE t1.name = 'ELECTRONICS' AND t4.name = 'FLASH';
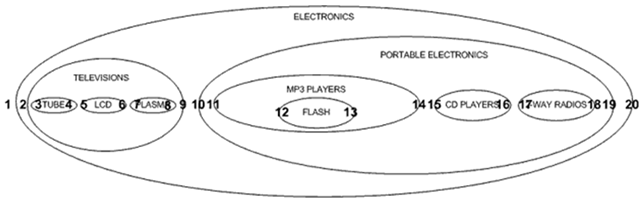
SELECT node.name FROM nested_category AS node, nested_category AS parent WHERE node.lft BETWEEN parent.lft AND parent.rgt AND parent.name = 'ELECTRONICS' ORDER BY node.lft;
SELECT name FROM nested_category WHERE rgt = lft + 1;
+--------------+ | name | +--------------+ | TUBE | | LCD | | PLASMA | | FLASH | | CD PLAYERS | | 2 WAY RADIOS | +--------------+
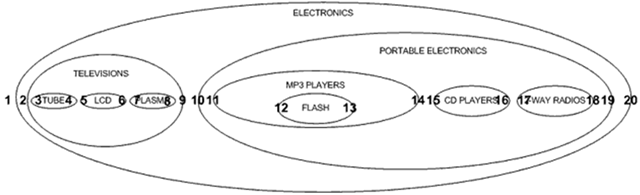
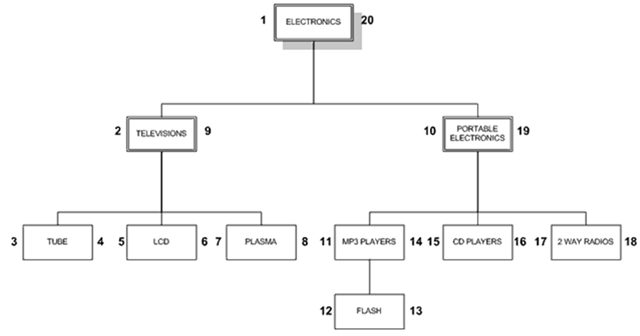
检索单一路径 在嵌套集合模型中,我们可以不用多个自连接就可以检索出单一路径:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
SELECT parent.name FROM nested_category AS node, nested_category AS parent WHERE node.lft BETWEEN parent.lft AND parent.rgt AND node.name = 'FLASH' ORDER BY parent.lft;
SELECT node.name, (COUNT(parent.name) - 1) AS depth FROM nested_category AS node, nested_category AS parent WHERE node.lft BETWEEN parent.lft AND parent.rgt GROUP BY node.name ORDER BY node.lft;
SELECT CONCAT( REPEAT(' ', COUNT(parent.name) - 1), node.name) AS name FROM nested_category AS node, nested_category AS parent WHERE node.lft BETWEEN parent.lft AND parent.rgt GROUP BY node.name ORDER BY node.lft;
SELECT node.name, (COUNT(parent.name) - (sub_tree.depth + 1)) AS depth FROM nested_category AS node, nested_category AS parent, nested_category AS sub_parent, ( SELECT node.name, (COUNT(parent.name) - 1) AS depth FROM nested_category AS node, nested_category AS parent WHERE node.lft BETWEEN parent.lft AND parent.rgt AND node.name = 'PORTABLE ELECTRONICS' GROUP BY node.name ORDER BY node.lft )AS sub_tree WHERE node.lft BETWEEN parent.lft AND parent.rgt AND node.lft BETWEEN sub_parent.lft AND sub_parent.rgt AND sub_parent.name = sub_tree.name GROUP BY node.name ORDER BY node.lft;
SELECT node.name, (COUNT(parent.name) - (sub_tree.depth + 1)) AS depth FROM nested_category AS node, nested_category AS parent, nested_category AS sub_parent, ( SELECT node.name, (COUNT(parent.name) - 1) AS depth FROM nested_category AS node, nested_category AS parent WHERE node.lft BETWEEN parent.lft AND parent.rgt AND node.name = 'PORTABLE ELECTRONICS' GROUP BY node.name ORDER BY node.lft )AS sub_tree WHERE node.lft BETWEEN parent.lft AND parent.rgt AND node.lft BETWEEN sub_parent.lft AND sub_parent.rgt AND sub_parent.name = sub_tree.name GROUP BY node.name HAVING depth <= 1 ORDER BY node.lft;
SELECT parent.name, COUNT(product.name) FROM nested_category AS node , nested_category AS parent, product WHERE node.lft BETWEEN parent.lft AND parent.rgt AND node.category_id = product.category_id GROUP BY parent.name ORDER BY node.lft;
SELECT CONCAT( REPEAT( ' ', (COUNT(parent.name) - 1) ), node.name) AS name FROM nested_category AS node, nested_category AS parent WHERE node.lft BETWEEN parent.lft AND parent.rgt GROUP BY node.name ORDER BY node.lft;
SELECT CONCAT( REPEAT( ' ', (COUNT(parent.name) - 1) ), node.name) AS name FROM nested_category AS node, nested_category AS parent WHERE node.lft BETWEEN parent.lft AND parent.rgt GROUP BY node.name ORDER BY node.lft;
SELECT CONCAT( REPEAT( ' ', (COUNT(parent.name) - 1) ), node.name) AS name FROM nested_category AS node, nested_category AS parent WHERE node.lft BETWEEN parent.lft AND parent.rgt GROUP BY node.name ORDER BY node.lft;
SELECT CONCAT( REPEAT( ' ', (COUNT(parent.name) - 1) ), node.name) AS name FROM nested_category AS node, nested_category AS parent WHERE node.lft BETWEEN parent.lft AND parent.rgt GROUP BY node.name ORDER BY node.lft;
SELECT CONCAT( REPEAT( ' ', (COUNT(parent.name) - 1) ), node.name) AS name FROM nested_category AS node, nested_category AS parent WHERE node.lft BETWEEN parent.lft AND parent.rgt GROUP BY node.name ORDER BY node.lft;
最后的思考 我希望这篇文章对你有所帮助,SQL中的嵌套集合的观念大约有十年的历史了,在网上和一些书中都能找到许多相关信息。在我看来,讲述分层数据的管理最全面的,是来自一本名叫《Joe Celko’s Trees and Hierarchies in SQL for Smarties》的书,此书的作者是在高级SQL领域倍受尊敬的Joe Celko。Joe Celko被认为是嵌套集合模型的创造者,更是该领域内的多产作家。我把Celko的书当作无价之宝,并极力地推荐它。在这本书中涵盖了在此文中没有提及的一些高级话题,也提到了其他一些关于邻接表和嵌套集合模型下管理分层数据的方法。 在随后的参考书目章节中,我列出了一些网络资源,也许对你研究分层数据的管理会有所帮助,其中包括一些PHP相关的资源(处理嵌套集合的PHP库)。如果你还在使用邻接表模型,你该去试试嵌套集合模型了,在Storing Hierarchical Data in a Database 文中下方列出的一些资源链接中能找到一些样例代码,可以去试验一下。
outdate_time = now() - 10s result = sql.query('update user_block_status set updated_time=now() where updated_time < ? orderby updated_time asclimit1', [outdate_time]) ## each worker can get different result.user_id